Every retrieval and every model call passes through the guardrail — classification, residency, redaction, routing. Confidential data cannot reach a model that isn't allowed to see it. Not by mistake, not by an insider, not by an operator overriding a setting. The substrate refuses the route — regardless of intent.
Each layer is swappable — you decide which you own. So you keep the systems and databases you already run: the Infozense substrate (Data · Tool · Guardrail) slots in between them and AI, making your organization AI-ready and compliant without replacing a thing.
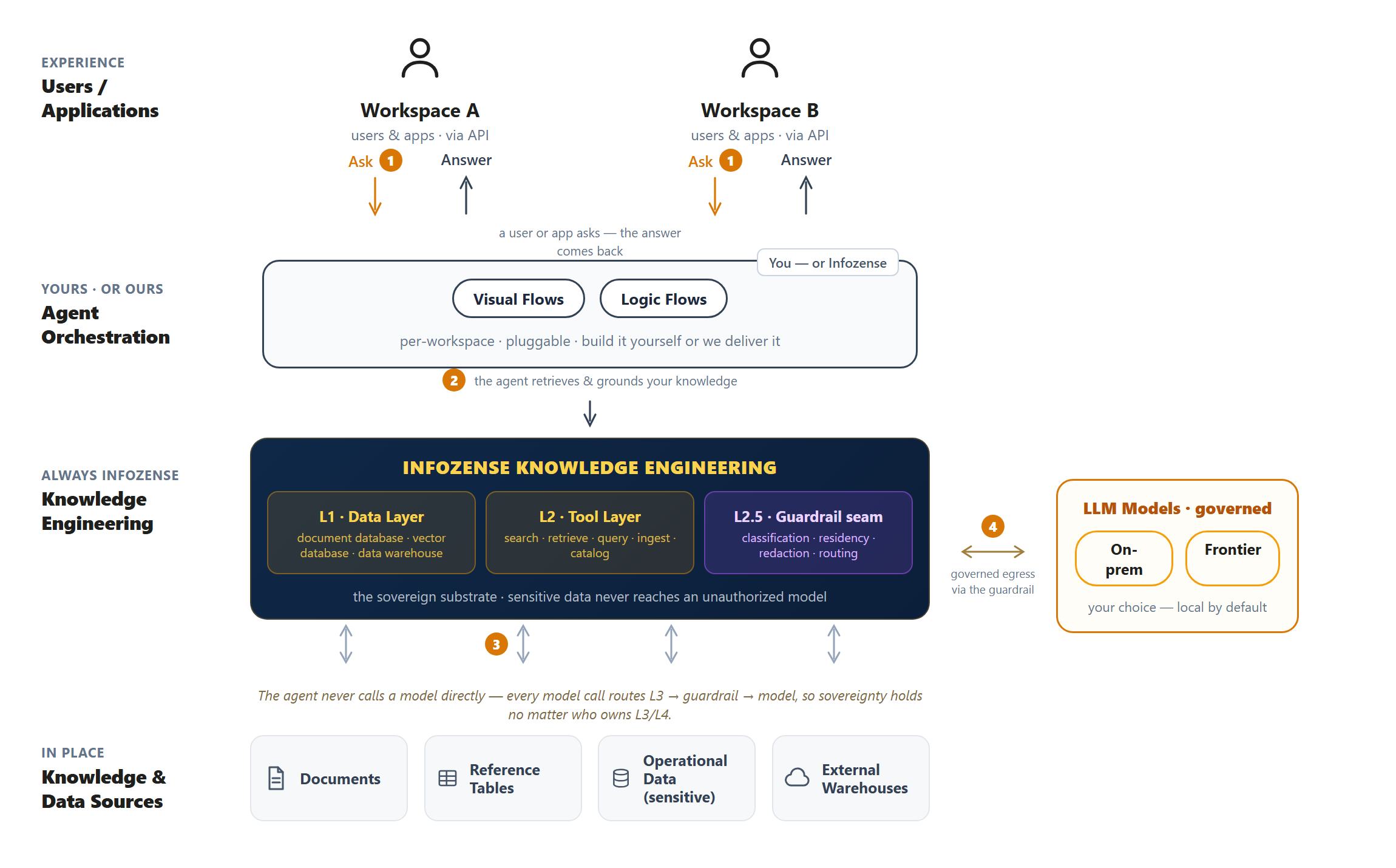
Infozense ships L1, L2, and the L2.5 guardrail seam — always. L3 and L4 are yours to build, fork our reference implementations, or have us deliver with proven open frameworks. Whoever builds the agent, every model call still routes through the guardrail — so the sovereignty guarantee never moves.
12–18 months across data, ML, and security teams. By the time it works, the LLM landscape has shifted twice.
Polished UX — but your data leaves your boundary, and compliance kills it before procurement finishes.
Easy to adopt, locked to one vendor. Federating your warehouse or switching vendors becomes a multi-quarter project.
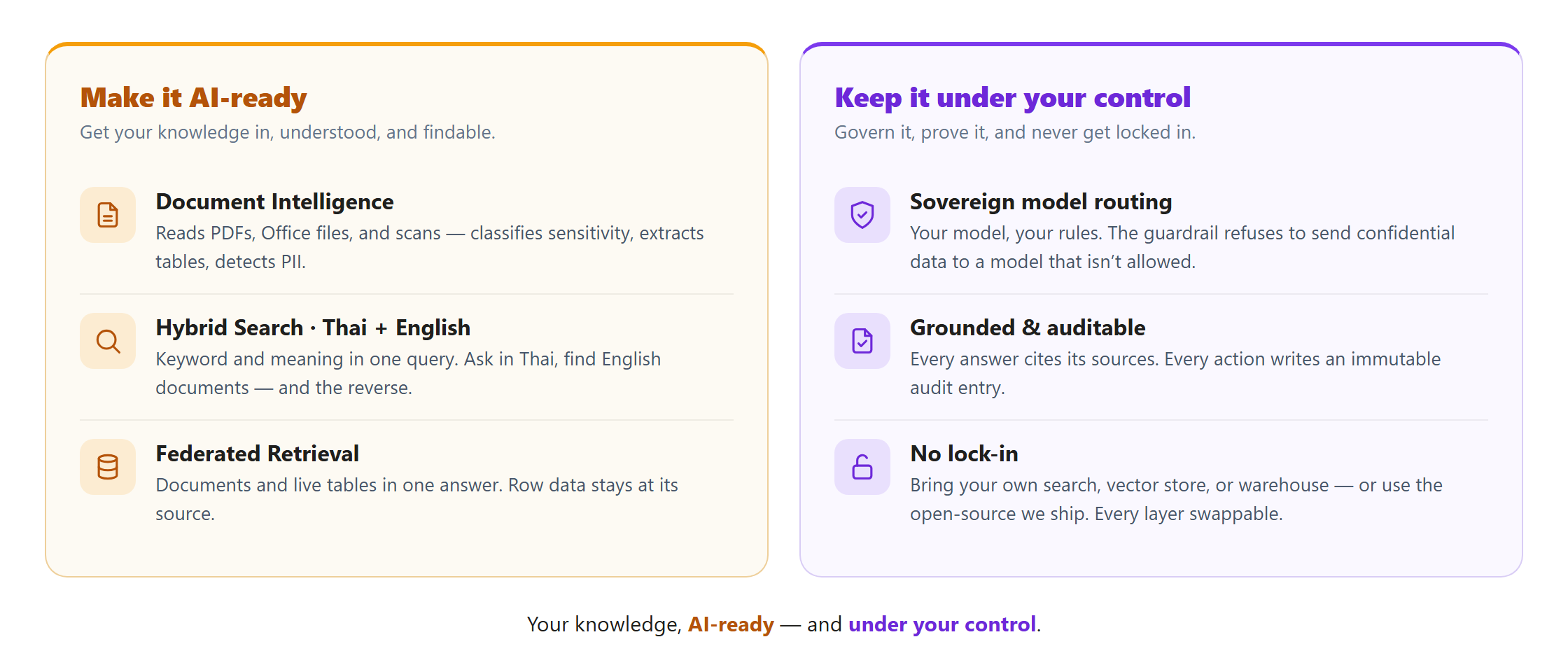
Your model, your rules. Register on-prem and frontier endpoints once; the guardrail routes by data classification and refuses to send confidential content to a model that isn't allowed — regardless of operator intent.
Documents and live tables in one answer — financial statements, factor returns, operational data — queried from the same chat that retrieves documents. Row data stays at source.
Reads PDFs, Office files, and scans (OCR included). Auto-classifies sensitivity, extracts text and tables, and detects PII — Thai national ID, phone, email, credit card.
Keyword and meaning in a single query. Ask in Thai, find English documents — and the reverse. Built for Southeast Asian enterprise.
Every answer cites its sources. Every retrieval, chat, ingest, and policy change writes an immutable audit entry — hand auditors a working API, not a slideshow. Built for Thai PDPA.
Use any search, vector store, or warehouse you like, open-source or commercial. Every layer is replaceable, with no proprietary glue underneath.
“How is this transaction taxed under the current VAT code?”
“What does the literature say about momentum-factor decay?”
“Who on staff has the skills for this project?”
…and more — IoT, Geospatial, Regulatory, Education, Legal, Healthcare. Same engine, same tool layer, different corpus.
What is true. Descriptive.
What will happen. Predictive.
What to do. Prescriptive.
Three layers of Intelligence Engineering. Knowledge comes first — you can't predict or decide on what you don't reliably know.
It runs where your data already lives. The model is your call — local by default, frontier when it matters; this is who runs the platform.
Your cloud or on-premise — AWS, GCP, Azure, IBM Cloud, INET, or bare metal. Full control over data and security, and we train your team to operate and scale it.
We host, operate, and optimize it for you — predictable monthly cost, auto-scaling and updates, live in days not months.
The software is the substrate; a successful deployment is people. Infozense engineers — the ones who build and operate it, not slide-deck consultants — work alongside your team for the first 8–16 weeks: discovery, ingestion, policy authoring, IdP integration, operator training. Knowledge-transfer first: your team owns the system at the end.
